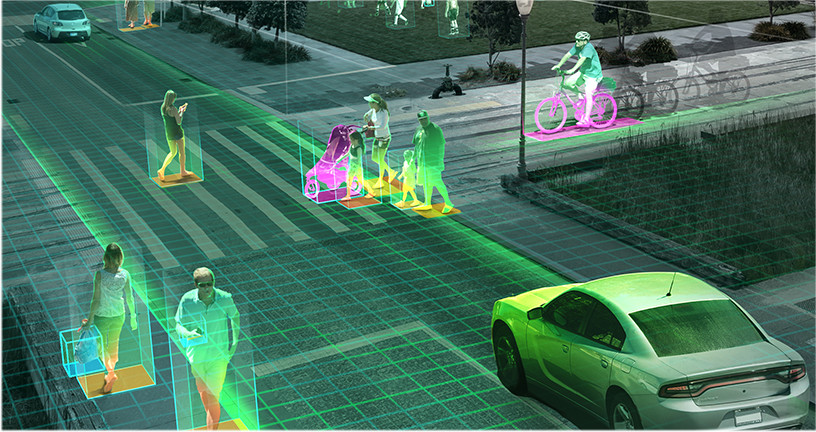
There's an explosion of demand for increasingly sophisticated AI-enabled services like image and speech recognition, natural language processing, visual search, and personalised recommendations. At the same time, data sets are growing, networks are getting more complex, and latency requirements are tightening to meet user expectations.
NVIDIA® TensorRT™ is a programmable inference accelerator that delivers the performance, efficiency, and responsiveness critical to powering the next generation of AI products and services—in the cloud, in the data center, at the network’s edge, and in vehicles.
NVIDIA deep learning inference software is the key to unlocking optimal inference performance. Using NVIDIA TensorRT, you can rapidly optimise, validate, and deploy trained neural networks for inference. TensorRT delivers up to 40X higher throughput in under seven milliseconds real-time latency when compared to CPU-only inference.
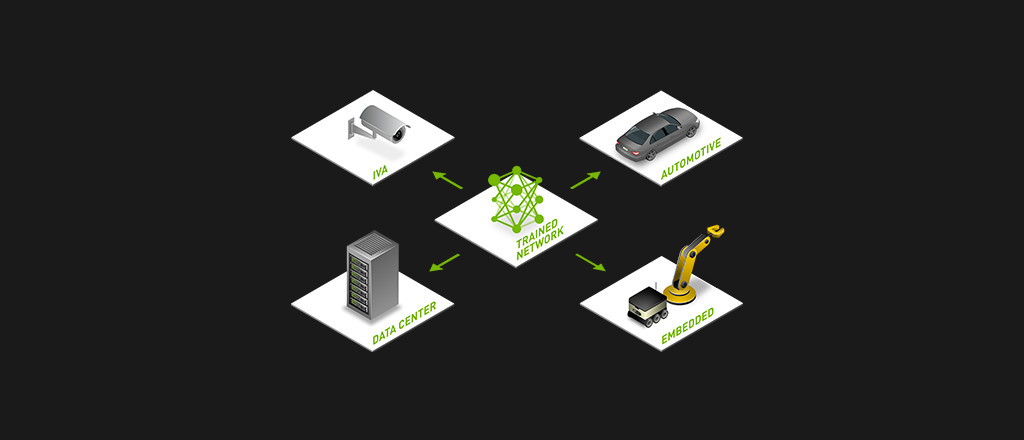
With one unified architecture, neural networks on every deep learning framework can be trained, optimised with NVIDIA TensorRT and then deployed for real-time inferencing at the edge. With NVIDIA® DGX™ systems, NVIDIA Tesla®, NVIDIA Jetson™, and NVIDIA DRIVE™ PX, NVIDIA has an end-to-end, fully scalable, deep learning platform available now.
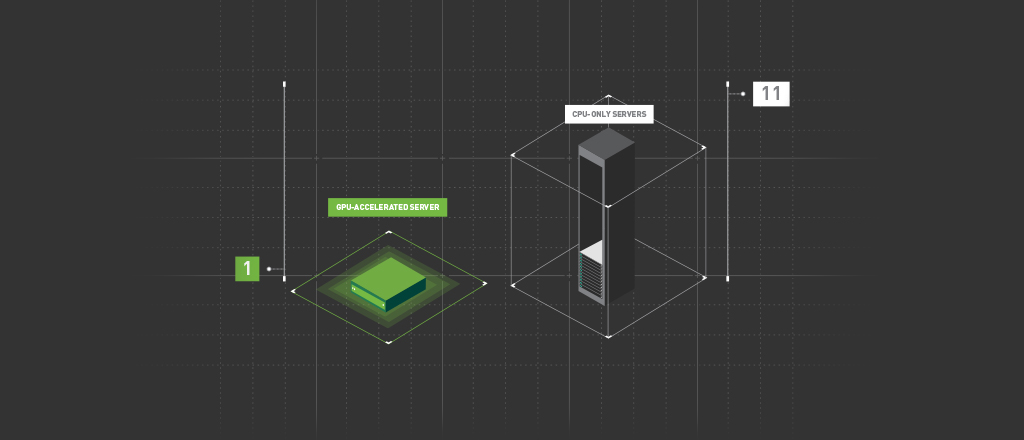
To keep servers at maximum productivity, data center managers must make tradeoffs between performance and efficiency. A single NVIDIA Tesla P4 server can replace eleven commodity CPU servers for deep learning inference applications and services, reducing energy requirements, and delivering cost savings of up to 80%.